
Versioning Files with Python, IPFS, and Pinata: A Comprehensive Guide
Harness the Power of Python and Pinata to Seamlessly Integrate with IPFS for Decentralized File Storage & Version Control


In this digital era of decentralization, maintaining accurate and organized versions is vital for collaboration and data integrity. In this comprehensive guide, we delve into the powerful combination of Python, IPFS (InterPlanetary File System), and Pinata to enable seamless versioning of files. By harnessing decentralized technology, we explore how to leverage Python scripts to interact with IPFS and Pinata, providing a secure and scalable solution for managing file versions. Join us on this journey to unlock the potential of decentralized file storage and enhance your file versioning capabilities. Do read the pre-requisite article on Pinata & IPFS here
Let's Get Going
Libraries
Configure
venvusingpython -m venv venvActivate
venvusingsource <path>/venv/bin/activateInstall Necessary Libraries
pip install pinatapy-vourhey
Setting up Pinata
Pinata Api and Pinata Secrets as discussed in the previous article are needed for this article too.
Keep the secrets safe, and don't push to the Internet.
Code
Libraries & Client
import os
import requests
from pinatapy import PinataPy
try:
# Connect to the IPFS cloud service
pinata_api_key="<>"
pinata_secret_api_key="<>"
pinata = PinataPy(pinata_api_key,pinata_secret_api_key)
print("Connected")
except Exception as e:
print(e)
print("Error connecting to IPFS")
Scenario 1 - No versioning.
Function
# def Upload the file
def upload_file_to_ipfs(file_path):
try:
if os.path.exists(file_path):
response = pinata.pin_file_to_ipfs(file_path)
return response
else:
print("File not found")
except Exception as e:
print(e)
print("Error uploading file to IPFS")
if __name__ == "__main__":
file_path = 'random.txt'
result = upload_file_to_ipfs(file_path)
print(result)
print(result['IpfsHash'])
The
upload_file_to_ipfsfunction uploads a file to IPFS using Pinata.It takes a
file_pathparameter representing the path to the file to be uploaded.It checks if the file exists at the given path.
If the file exists, it calls
pinata.pin_file_to_ipfs(file_path)to upload the file to IPFS using Pinata.The response object containing information about the uploaded file, such as the IPFS hash, is returned.
When different versions of the same file random.txt are uploaded, this block, just returns different Hashes every time, without maintaining Versions.
Version 1:
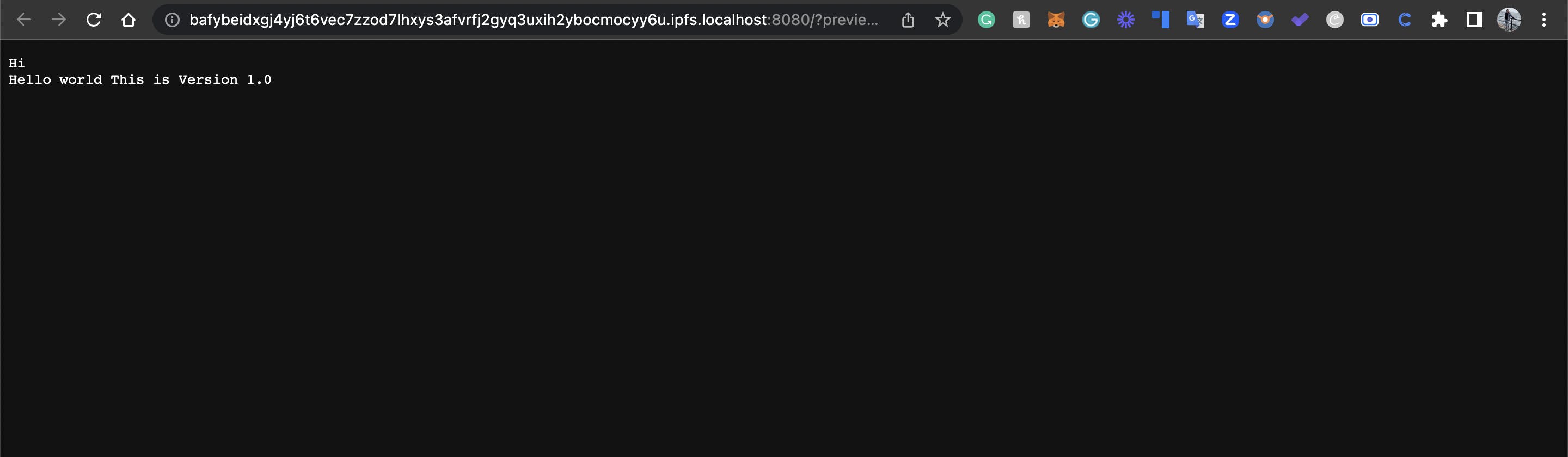
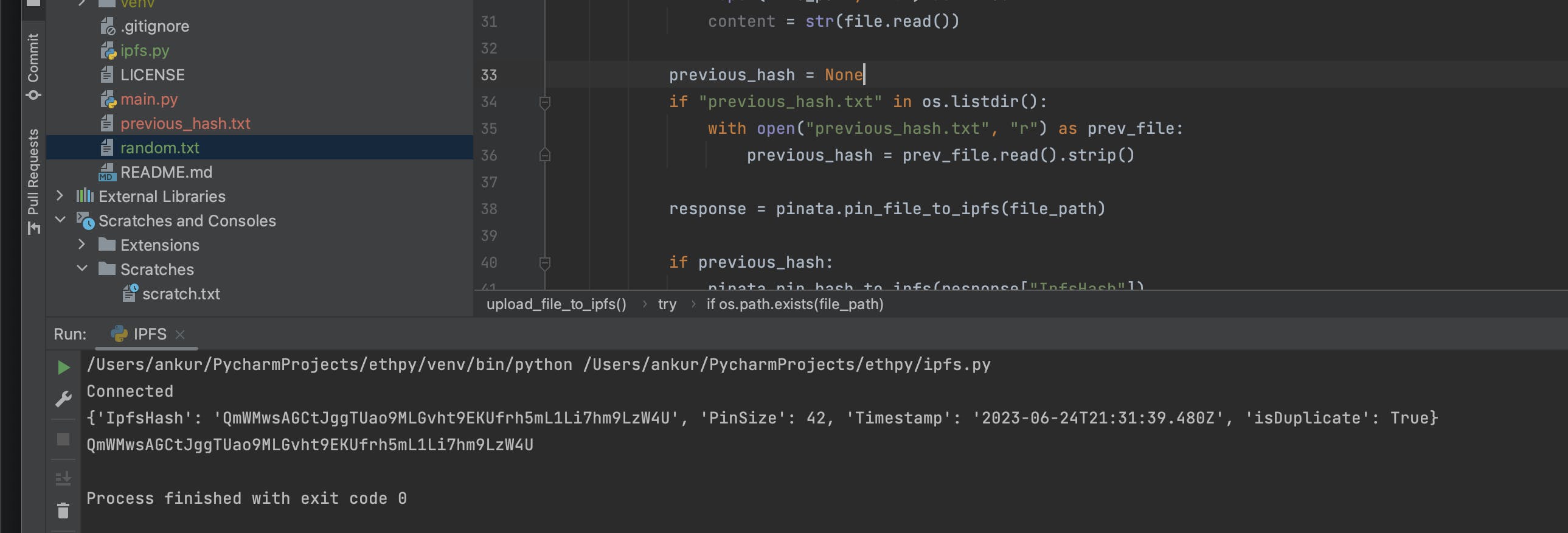
If you re-run code with the same file, the same hash is obtained again, new entries aren't created.

Version 2:


On IPFS it looks like 2 different files with the same name for 2 different versions

Our goal is to have a LinkedList-like function, where the CID of the current version, can store the hash to the previous version.
In IPFS (InterPlanetary File System), versioning is not built-in natively like a traditional version control system. However, IPFS provides the necessary tools and flexibility to implement versioning on top of its protocol. Here's an explanation of how versioning can be achieved in IPFS:
Content Addressing: IPFS uses content addressing to uniquely identify and retrieve files. Each file or block in IPFS is identified by its content hash, which is derived from the file's content. The content hash serves as a unique identifier for the file, regardless of its location or version.
Immutable Data: In IPFS, files are immutable, meaning that once a file is added to the network, its content cannot be changed. To update a file, a new version is created with the desired changes.
Content-Defined Chunking: IPFS breaks files into smaller chunks called blocks. Content-defined chunking splits files at specific boundaries based on their content, ensuring that similar content results in the same chunk. This feature is crucial for efficient versioning.
MerkleDAG: IPFS uses a data structure called MerkleDAG (Directed Acyclic Graph) to represent and link files and their versions. Each version of a file is represented as a separate MerkleDAG node, and the nodes are linked together to form a tree-like structure.
Linking Versions: To link different versions of a file, IPFS allows you to create a MerkleDAG node for each version, with the content hash of the previous version included as a link. This way, you can traverse the tree of versions and retrieve any specific version of a file by following the appropriate links.
Mutable File System (MFS): IPFS provides a feature called Mutable File System (MFS), which allows you to create a mutable namespace on top of the immutable IPFS content. MFS provides a familiar file system interface and allows you to manage named files and directories. By creating new versions of files in MFS and linking them appropriately, you can effectively achieve versioning in IPFS.
Content Publishing: Once you have updated a file and created a new version, you can publish the new version to the IPFS network. This involves adding the new version to IPFS and obtaining its content hash. You can then share this content hash with others to allow them to access the specific version of the file.
Thus, the User has to take care of versioning while uploading.
Scenario 2 - Versioning
def upload_file_to_ipfs(file_path):
try:
if os.path.exists(file_path):
with open(file_path, "rb") as file:
content = str(file.read())
previous_hash = None
if "previous_hash.txt" in os.listdir():
with open("previous_hash.txt", "r") as prev_file:
previous_hash = prev_file.read().strip()
response = pinata.pin_file_to_ipfs(file_path)
if previous_hash:
pinata.pin_hash_to_ipfs(response["IpfsHash"])
response["PreviousHash"] = previous_hash
with open("previous_hash.txt", "w") as prev_file:
prev_file.write(response["IpfsHash"])
return response
else:
print("File not found")
except Exception as e:
print(e)
print("Error uploading file to IPFS")
if __name__ == "__main__":
file_path = 'random_new.txt'
result = upload_file_to_ipfs(file_path)
print(result)
print(result['IpfsHash'])
If there is a previous hash, it calls
pinata.pin_hash_to_ipfs(response["IpfsHash"])to pin the newly uploaded file version to IPFS using the previous hash. It also adds the previous hash to theresponseobject under the "PreviousHash" key.The function opens the "previous_hash.txt" file in write mode using
open("previous_hash.txt", "w")and writes the IPFS hash of the current version to it usingprev_file.write(response["IpfsHash"]).
For a new file random_new.txt
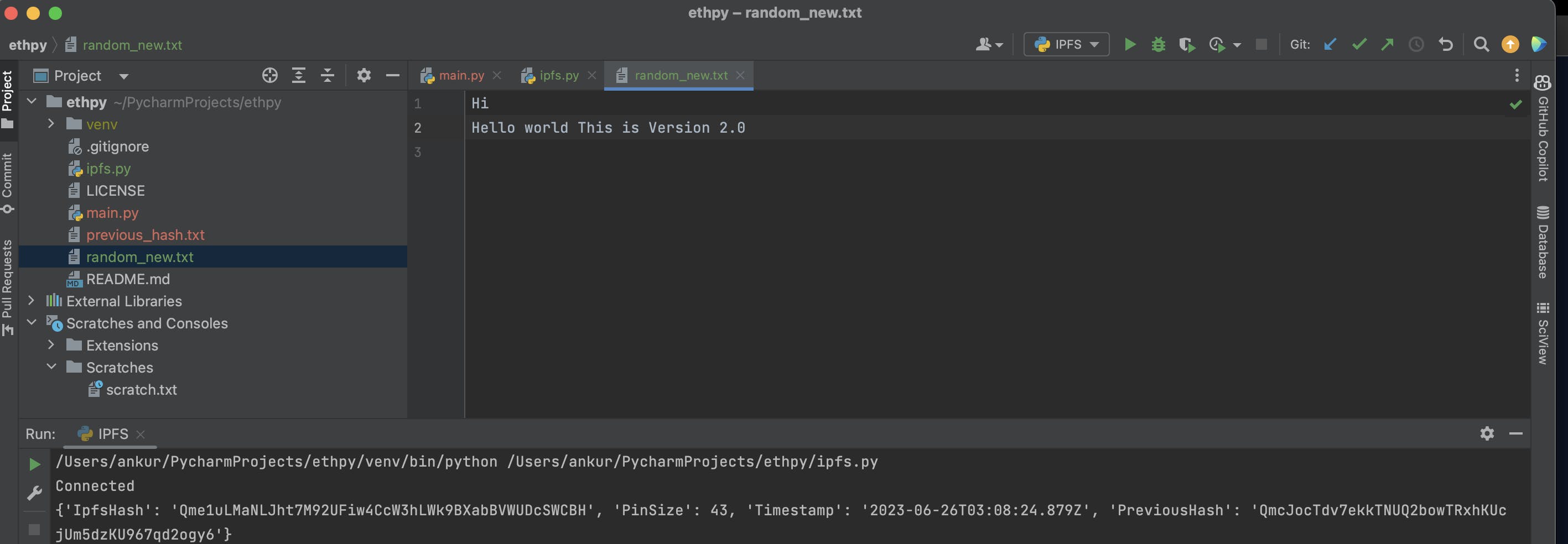
Observe that version 2 file has previous hash pointing to version 1.0 file.

Although the cloud still has 2 entries, but the version 2 of file, has hash of version 1 in metadata called CID.
CID
In IPFS (InterPlanetary File System), CID stands for Content Identifier. It is a unique identifier that represents the content of a file or any other data stored in IPFS. CIDs are used as immutable references to the content, allowing for easy retrieval and verification.
CID consists of two main components:
Content Identifier: This component represents the hash of the content, which is generated using cryptographic hashing algorithms such as SHA-2 (256-bit or 512-bit), SHA-3, or others. The hash is computed from the content's data, making it unique for each piece of content.
Content Addressing Method: This component indicates the addressing method used to construct the CID. IPFS supports different multibase encoding methods, such as Base58btc, Base32, or Base16, to represent the CID.
CID plays a vital role in IPFS by enabling decentralized addressing and retrieval of content. It provides a secure and tamper-evident way to reference files and data stored within the IPFS network. By using CIDs, users can easily verify the integrity and authenticity of content, regardless of its location in the distributed IPFS network.
Conclusion
In conclusion, we have explored the powerful combination of Python, IPFS (InterPlanetary File System), and Pinata for versioning files in a decentralized manner. By leveraging IPFS's content addressing and Pinata's cloud service, we can seamlessly upload and manage file versions while ensuring data integrity and collaboration. The code examples provided demonstrate how to connect to IPFS, upload files, track versions, and retrieve specific versions. Leveraging CIDs, the content identifiers in IPFS, allows for efficient referencing and verification of file versions. With Python, IPFS, and Pinata, we unlock the potential for secure and scalable file versioning, enabling efficient collaboration and robust data management in decentralized environments.