
Harnessing the Power of Azure Language Model with Python: A Comprehensive Guide to Advanced NLP Tasks


Unleash the Full Potential of Azure Text Analytics to Detect Language, Extract Key Phrases, Analyze Sentiment with Opinion Mining, Recognize Entities, and More Using Python
In this article, we will learn how to harness the power of the Azure Language Model using Python for advanced natural language processing (NLP) tasks. By exploring step-by-step code examples and the functionalities of Azure's Text Analytics service, we will perform language detection, key phrase extraction, sentiment analysis with opinion mining and abstract summarization. Learn more about Azure AI offerings here
What is Azure Language
The Azure Language Model, part of Microsoft's Azure cloud platform, is an advanced natural language processing (NLP) solution (SAAS) that empowers businesses to extract valuable insights from text data. With a user-friendly Python SDK, it offers functionalities like language detection, sentiment analysis, key phrase extraction, entity recognition, linked entity recognition, and abstract summarization. Leveraging this powerful tool, organizations can gain meaningful context from unstructured text, enabling informed decision-making and deeper understanding of customer feedback, user sentiments, and market trends. Learn more here
Let's Begin
Step 1 - Setting Up Azure Language
Head on to Azure Portal and login with credentials
Create a New Language Service, under AI+ Machine Learning Resources

- For this experiment, we utilise NLP functionality like Entity Recognition, Sentiment Analysis etc.
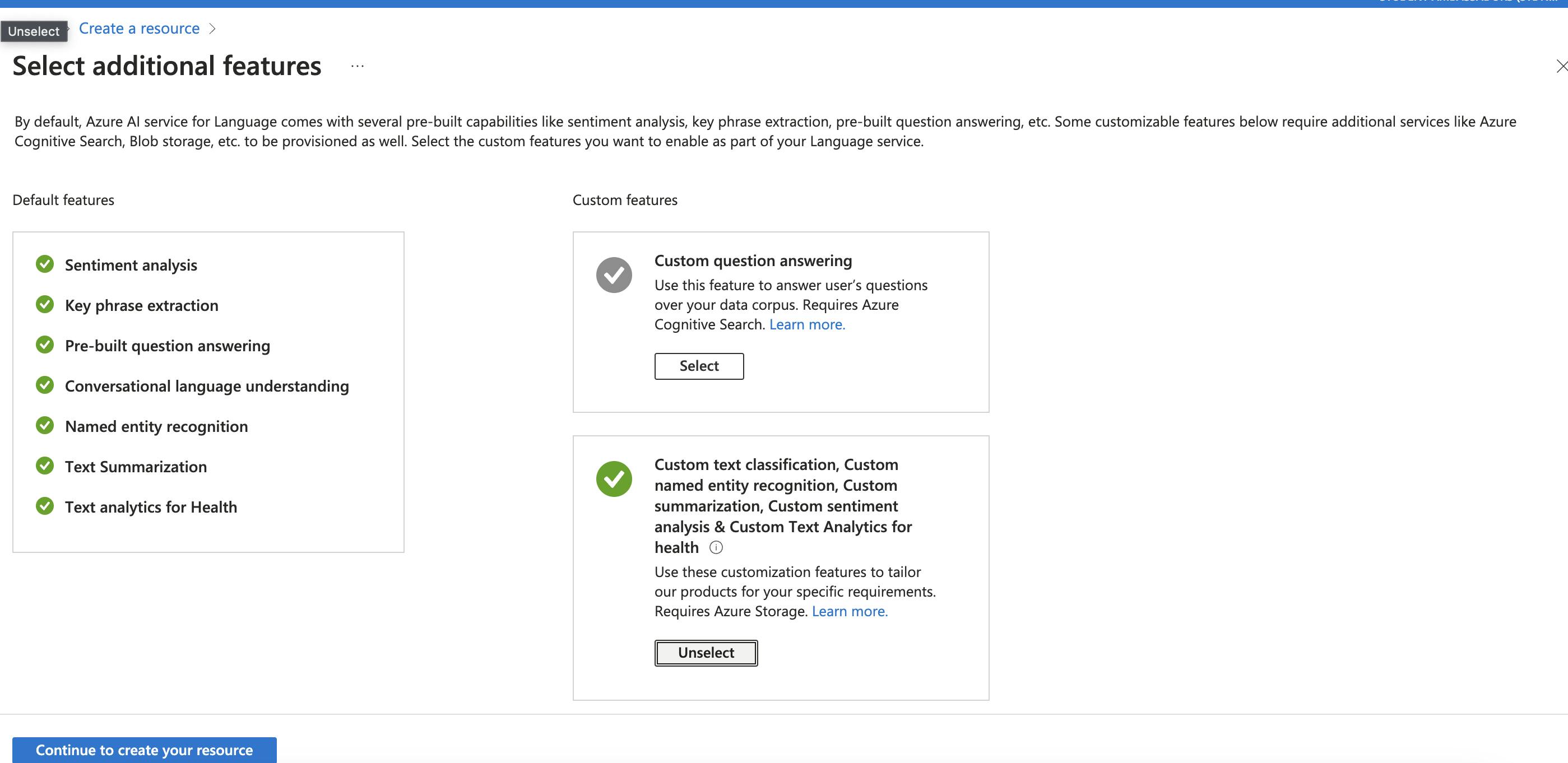
- Continue to Create Resource, add details of Resource Group & Pricing Tier, based on usage
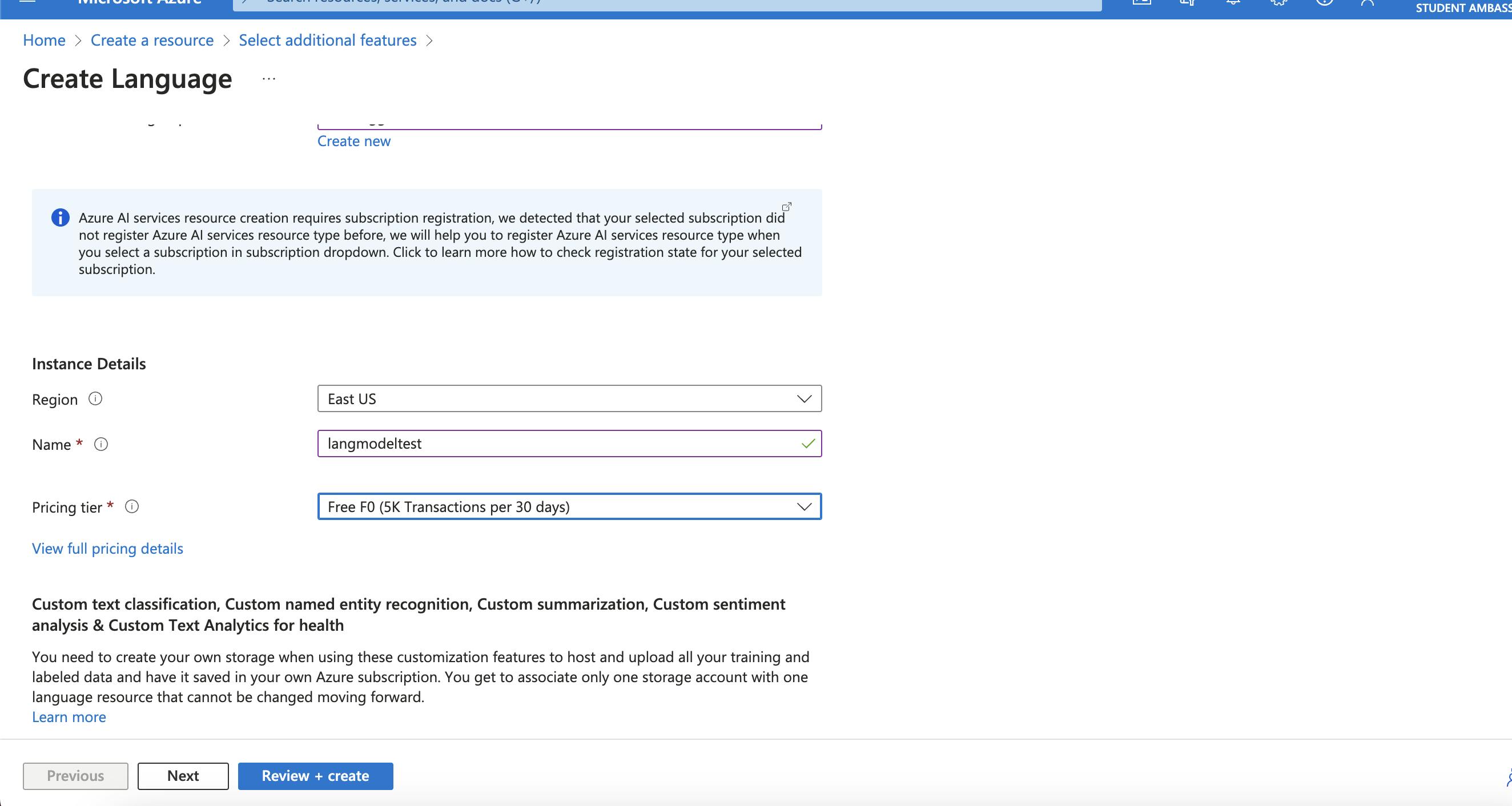
- Furthermore, Add details of associated Blob storage account
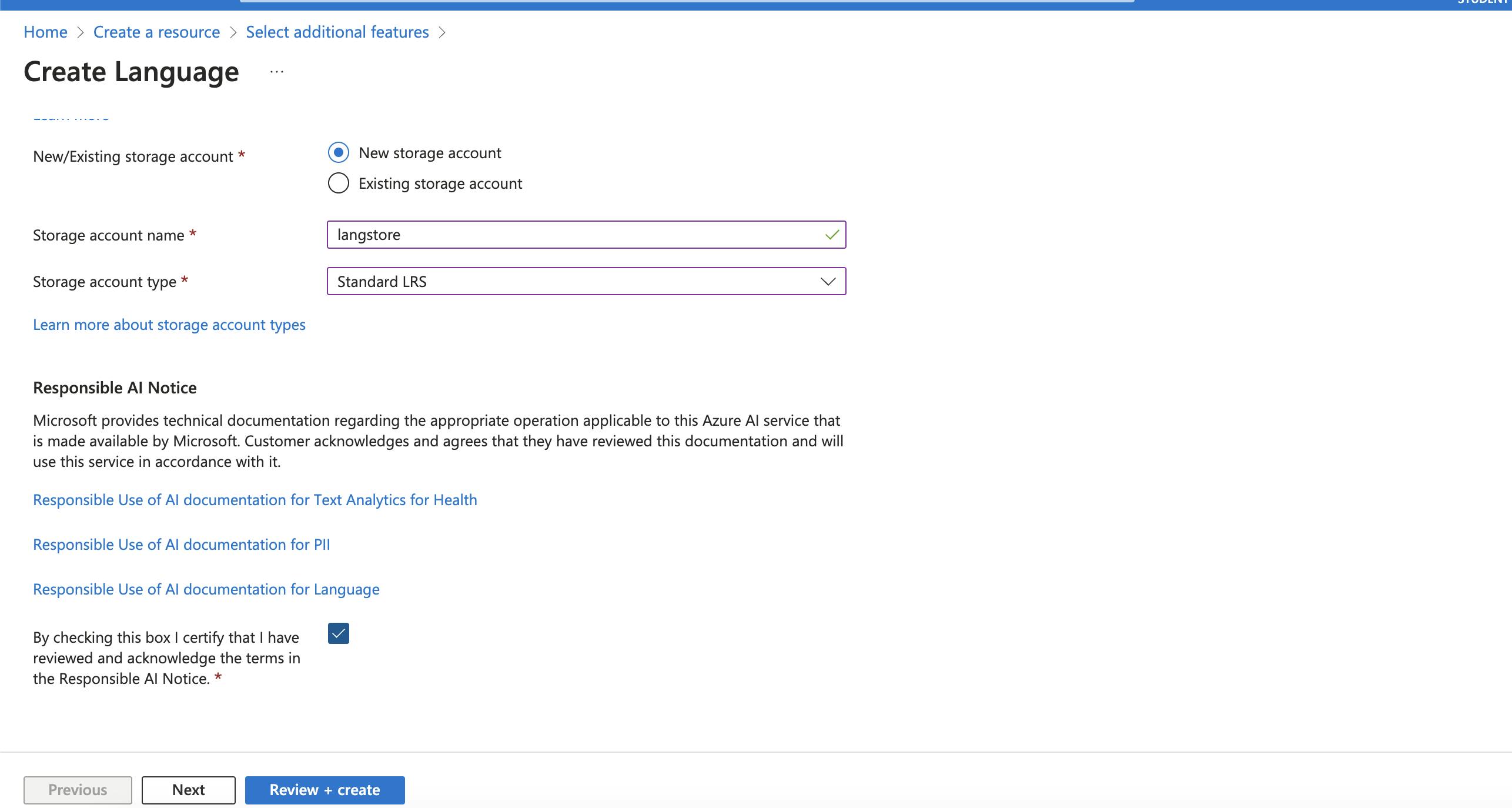
- Click Review+ create and Create Resource
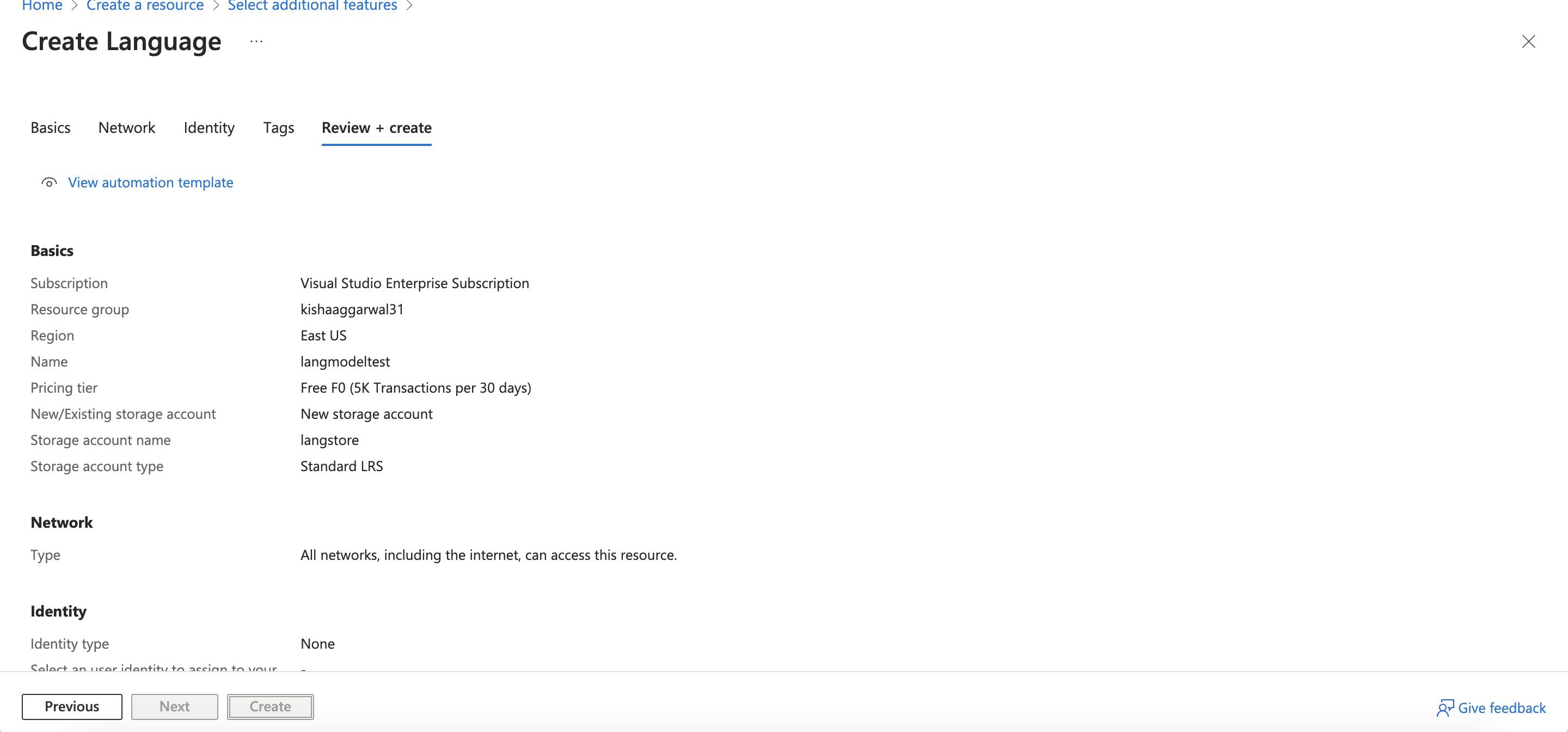
- Wait for Deployment to get complete
- Open Resources and Review the overview
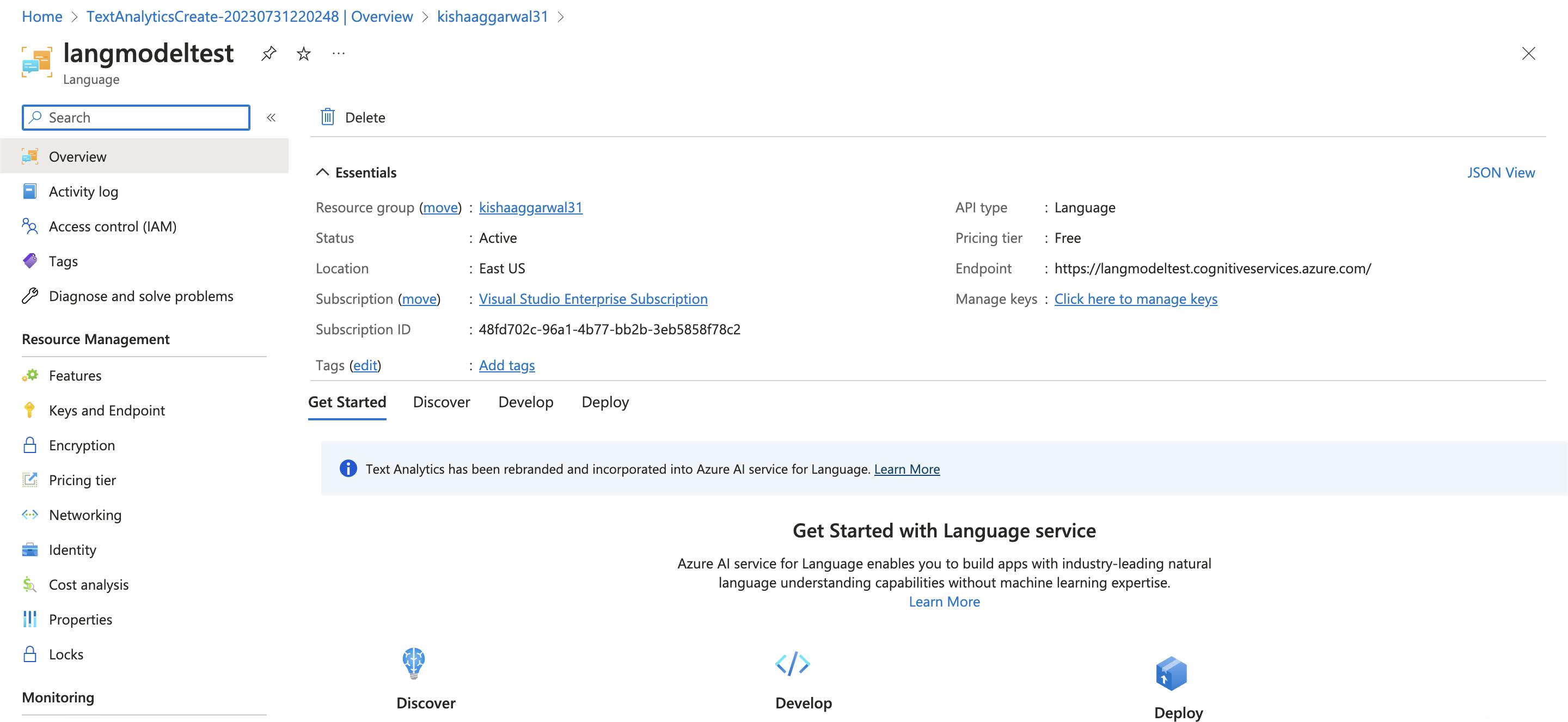
- Check Keys and Endpoints to copy the endpoint and Key.
- Under networking Enable All networks
- Explore Cost Analysis, Properties to know more.
Step 2 Installing Libraries
python3 -m venv venvsource venv/bin/activatepip install azure-ai-textanalytics --pre
Step 3 Code
Client
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import TextAnalyticsClient
import os
#define the connection parameter
endpoint = "https://langmodeltest.cognitiveservices.azure.com/"
key = <KEY>
#Create client
credential = AzureKeyCredential(key)
text_analytics_client = TextAnalyticsClient(endpoint=endpoint, credential=credential)
Sample Article
'''
Sample Article from Wikipedia
'''
documents = ["The Times is a British daily national newspaper based in London. It began in 1785 under the title The Daily Universal Register, adopting its current name on 1 January 1788. The Times and its sister paper The Sunday Times (founded in 1821) are published by Times Media, since 1981 a subsidiary of News UK, in turn wholly owned by News Corp. The Times and The Sunday Times, which do not share editorial staff, were founded independently and have had common ownership only since 1966.[3] In general, the political position of The Times is considered to be centre-right.[4]The Times is the first newspaper to have borne that name, lending it to numerous other papers around the world, such as The Times of India and The New York Times. In countries where these other titles are popular, the newspaper is often referred to as The London Times,[5][6] or as The Times of London,[7] although the newspaper is of national scope and distribution. It is considered a newspaper of record in the UK.[8]The Times had an average daily circulation of 365,880 in March 2020; in the same period, The Sunday Times had an average weekly circulation of 647,622.[2] The two newspapers also had 304,000 digital-only paid subscribers as of June 2019.[9] An American edition of The Times has been published since 6 June 2006.[10] The Times has been heavily used by scholars and researchers because of its widespread availability in libraries and its detailed index. A complete historical file of the digitised paper, up to 2019, is online from Gale Cengage Learning"]
Functions
Language Detection
#detect the language response = text_analytics_client.detect_language(documents, country_hint="us") for document in response: print("Document Id: ", document.id, ", Language: ", document.primary_language.name)Output:
Document Id: 0 , Language: English* text_analytics_client.detect_language(): This method is called on thetext_analytics_clientobject to detect the language of the documents. It takes thedocumentslist as input and returns a response object.* document.primary_language.name: This retrieves the detected primary language of the current document. The language is returned as a string.Key Phrase Detection
#detect the key phrases
response = text_analytics_client.extract_key_phrases(documents)
for document in response:
print("Document Id: ", document.id)
print("\tKey Phrases:")
for phrase in document.key_phrases:
print("\t\t", phrase)
Output
Document Id: 0
Key Phrases:
The Daily Universal Register
The New York Times
British daily national newspaper
average daily circulation
average weekly circulation
304,000 digital-only paid subscribers
complete historical file
Gale Cengage Learning
numerous other papers
The Sunday Times
The London Times
national scope
The Times
other titles
Times Media
News Corp.
editorial staff
common ownership
political position
same period
two newspapers
American edition
widespread availability
detailed index
first newspaper
current name
sister paper
News UK
1 January
subsidiary
turn
world
India
countries
distribution
record
March
June
scholars
researchers
libraries
digitised
text_analytics_client.extract_key_phrases(): This method is called on thetext_analytics_clientobject to extract key phrases from the documents. It takes thedocumentslist as input and returns a response object.document.key_phrases: This retrieves the list of key phrases that were extracted from the current document. The key phrases are returned as a list of strings.
- Sentiment Analysis
#detect the sentiment with opinion
response = text_analytics_client.analyze_sentiment(documents, show_opinion_mining=True)
doc_result = [doc for doc in response if not doc.is_error]
positive_reviews = [doc for doc in doc_result if doc.sentiment == "positive"]
mixed_reviews = [doc for doc in doc_result if doc.sentiment == "mixed"]
negative_reviews = [doc for doc in doc_result if doc.sentiment == "negative"]
Output:
Document Sentiment: neutral
...We have 0 positive reviews, 0 mixed reviews, and 0 negative reviews.
text_analytics_client.analyze_sentiment(): This method is called on thetext_analytics_clientobject to analyze the sentiment of the documents. It takes thedocumentslist as input and returns a response object.positive_reviews,mixed_reviews,negative_reviews: These variables use list comprehension to separate the documents with positive, mixed, and negative sentiments from thedoc_result.
- Named Entity Detection
#detect the entities
result = text_analytics_client.recognize_entities(documents)
result = [review for review in result if not review.is_error]
for idx, review in enumerate(result):
for entity in review.entities:
print(f"Entity '{entity.text}' has category '{entity.category}'")
Output
Positive reviews:
Entity 'The Times' has category 'Organization'
Entity 'daily' has category 'DateTime'
Entity 'newspaper' has category 'Product'
Entity 'London' has category 'Location'
Entity '1785' has category 'DateTime'
Entity 'Daily' has category 'DateTime'
Entity '1 January 1788' has category 'DateTime'
Entity 'The Times' has category 'Organization'
Entity 'The Sunday Times' has category 'Organization'
Entity '1821' has category 'DateTime'
Entity 'Times Media' has category 'Organization'
Entity 'since 1981' has category 'DateTime'
Entity 'News UK' has category 'Organization'
Entity 'News Corp' has category 'Organization'
Entity 'The Times' has category 'Organization'
Entity 'The Sunday Times' has category 'Organization'
Entity 'editorial' has category 'Skill'
Entity 'since 1966' has category 'DateTime'
Entity '3' has category 'Quantity'
Entity 'political' has category 'Skill'
Entity 'The Times' has category 'Organization'
Entity '4' has category 'Quantity'
Entity 'The Times' has category 'Organization'
Entity 'first' has category 'Quantity'
Entity 'The Times of India' has category 'Organization'
Entity 'The New York Times' has category 'Organization'
Entity 'newspaper' has category 'Product'
Entity 'The London Times' has category 'Organization'
Entity '5' has category 'Quantity'
Entity '6' has category 'Quantity'
Entity 'The Times of London' has category 'Organization'
Entity '7' has category 'Quantity'
Entity 'newspaper' has category 'Product'
Entity 'newspaper' has category 'Product'
Entity 'UK' has category 'Location'
Entity '8' has category 'Quantity'
Entity 'The Times' has category 'Organization'
Entity 'daily' has category 'DateTime'
Entity '365,880' has category 'Quantity'
Entity 'March 2020' has category 'DateTime'
Entity 'The Sunday Times' has category 'Organization'
Entity 'weekly' has category 'DateTime'
Entity '647,622' has category 'Quantity'
Entity '2' has category 'Quantity'
Entity 'two' has category 'Quantity'
Entity 'newspapers' has category 'Product'
Entity '304,000' has category 'Quantity'
Entity 'subscribers' has category 'PersonType'
Entity 'June 2019' has category 'DateTime'
Entity '9' has category 'Quantity'
Entity 'The' has category 'Organization'
Entity 'Times' has category 'Product'
Entity 'since 6 June 2006' has category 'DateTime'
Entity '10' has category 'Quantity'
Entity 'The Times' has category 'Organization'
Entity 'scholars' has category 'PersonType'
Entity 'researchers' has category 'PersonType'
Entity 'libraries' has category 'Location'
Entity '2019' has category 'DateTime'
Entity 'Gale Cengage Learning' has category 'Organization'
text_analytics_client.recognize_entities(): This method is called on thetext_analytics_clientobject to recognize entities in the documents. It takes thedocumentslist as input and returns a response object.review.entities: This retrieves the list of entities recognized in the current document (review) within the iteration. An entity represents a specific piece of information in the text, such as a person's name, location, organization, or date.
- Linked Entity
#detect the linked entities
response = text_analytics_client.recognize_linked_entities(documents)
for document in response:
print("Document Id: ", document.id)
print("\tLinked Entities:")
for entity in document.entities:
print("\t\tName: ", entity.name, "\tId: ", entity.data_source_entity_id, "\tUrl: ", entity.url,
"\n\t\tData Source: ", entity.data_source)
print("\t\tMatches:")
for match in entity.matches:
print("\t\t\tText:", match.text)
print("\t\t\tConfidence Score: {0:.2f}".format(match.confidence_score))
Output
Document Id: 0
Linked Entities:
Name: The Times Id: The Times Url: https://en.wikipedia.org/wiki/The_Times
Data Source: Wikipedia
Matches:
Text: The Daily Universal Register
Confidence Score: 0.95
Text: The Times of London
Confidence Score: 0.94
Text: The London Times
Confidence Score: 0.95
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Text: The Times
Confidence Score: 0.05
Name: United Kingdom Id: United Kingdom Url: https://en.wikipedia.org/wiki/United_Kingdom
Data Source: Wikipedia
Matches:
Text: British
Confidence Score: 0.11
Text: the UK
Confidence Score: 0.20
Name: London Id: London Url: https://en.wikipedia.org/wiki/London
Data Source: Wikipedia
Matches:
Text: London
Confidence Score: 0.29
Name: January 1 Id: January 1 Url: https://en.wikipedia.org/wiki/January_1
Data Source: Wikipedia
Matches:
Text: 1 January
Confidence Score: 0.21
Name: The New York Times Id: The New York Times Url: https://en.wikipedia.org/wiki/The_New_York_Times
Data Source: Wikipedia
Matches:
Text: The New York Times
Confidence Score: 0.48
Text: The Sunday Times
Confidence Score: 0.10
Text: The Sunday Times
Confidence Score: 0.10
Text: The Sunday Times
Confidence Score: 0.10
Text: Times
Confidence Score: 0.10
Text: The
Confidence Score: 0.52
Name: News media Id: News media Url: https://en.wikipedia.org/wiki/News_media
Data Source: Wikipedia
Matches:
Text: Media
Confidence Score: 0.02
Name: News UK Id: News UK Url: https://en.wikipedia.org/wiki/News_UK
Data Source: Wikipedia
Matches:
Text: News Corp.
Confidence Score: 0.09
Text: News UK
Confidence Score: 0.91
Name: India Id: India Url: https://en.wikipedia.org/wiki/India
Data Source: Wikipedia
Matches:
Text: In
Confidence Score: 0.22
Name: The Times of India Id: The Times of India Url: https://en.wikipedia.org/wiki/The_Times_of_India
Data Source: Wikipedia
Matches:
Text: The Times of India
Confidence Score: 0.46
Name: United States Id: United States Url: https://en.wikipedia.org/wiki/United_States
Data Source: Wikipedia
Matches:
Text: American
Confidence Score: 0.17
Name: June 6 Id: June 6 Url: https://en.wikipedia.org/wiki/June_6
Data Source: Wikipedia
Matches:
Text: 6 June
Confidence Score: 0.36
Name: Gale (publisher) Id: Gale (publisher) Url: https://en.wikipedia.org/wiki/Gale_(publisher)
Data Source: Wikipedia
Matches:
Text: Gale Cengage Learning
Confidence Score: 0.75
text_analytics_client.recognize_linked_entities(): This method is called on thetext_analytics_clientobject to recognize linked entities in the documents. It takes thedocumentslist as input and returns a response object.entity.name: This prints the name of the linked entity.entity.data_source_entity_id: This prints the unique identifier associated with the linked entity in the external data source.entity.url: This prints the URL that provides more information about the linked entity.entity.data_source: This prints the name of the data source from which the linked entity information is extracted.entity.matches: This is a list of matches for the linked entity in the document. The linked entity may appear multiple times in the text, and each match provides details about a specific occurrence.
- Abstract Summary
#abstract_summary
response = text_analytics_client.begin_abstract_summary(documents)
abstract_summary_results = response.result()
for result in abstract_summary_results:
if result.kind == "AbstractiveSummarization":
print("Summaries abstracted:")
[print(f"{summary.text}\n") for summary in result.summaries]
elif result.is_error is True:
print("...Is an error with code '{}' and message '{}'".format(
result.error.code, result.error.message
))
Output
Summaries abstracted:
The Times is a British daily national newspaper based in London, founded in 1785 under the title The Daily Universal Register. It adopted its current name on 1 January 1788. The Times and its sister paper The Sunday Times are published by Times Media, a subsidiary of News UK, in turn wholly owned by News Corp. The Times is considered a newspaper of record in the UK and is considered centre-right in political terms. The Times has an average daily circulation of 365,880 and an average weekly circulation of 647,622. The Times has been heavily used by scholars and researchers because of its widespread availability in libraries and its detailed index.
text_analytics_client.begin_abstract_summary(): This method is called on thetext_analytics_clientobject to begin the process of generating abstractive summaries for the documents. It takes thedocumentslist as input and returns a response object.
Conclusion
In conclusion, this article demonstrated the remarkable capabilities of the Azure Language Model with Python's Azure SDK. By leveraging the Azure Text Analytics service, we explored a range of advanced natural language processing tasks, including language detection, key phrase extraction, sentiment analysis with opinion mining, entity recognition, linked entity recognition, and abstractive summarization. Through this comprehensive guide, developers and data scientists have gained valuable insights into language understanding and the transformative potential of the Azure Language Model. With its user-friendly interface and robust infrastructure, the Azure Language Model stands as an essential tool for unraveling valuable information from text data and making data-driven decisions across diverse industries.