
Harnessing the Power of Azure Cognitive Services: Speech API for Speech and Text Processing
A Developer's Guide to Building Voice-Enabled Applications


In the ever-evolving landscape of technology, voice interfaces and speech recognition have emerged as transformative tools, revolutionizing the way we interact with applications and devices. Azure Cognitive Services' Speech API stands at the forefront of this revolution, offering developers a powerful suite of tools to integrate speech-to-text, text-to-speech, and even emotion detection capabilities into their applications. In this comprehensive guide, we will delve into the intricacies of Azure's Speech API, exploring its diverse functionalities and demonstrating how it empowers developers to create more engaging, accessible, and emotionally-aware applications. Check out the Documentation here before diving into the article
What is Azure Speech
The Speech service provides speech-to-text and text-to-speech capabilities with a Speech resource. You can transcribe speech-to-text with high accuracy, produce natural-sounding text-to-speech voices, translate spoken audio, and use speaker recognition during conversations. Learn more here
Let's Begin
Step 1 - Setting Up Azure Speech
Head on to Azure Portal and login with credentials
Create a new Speech Service under AI + Machine Learning

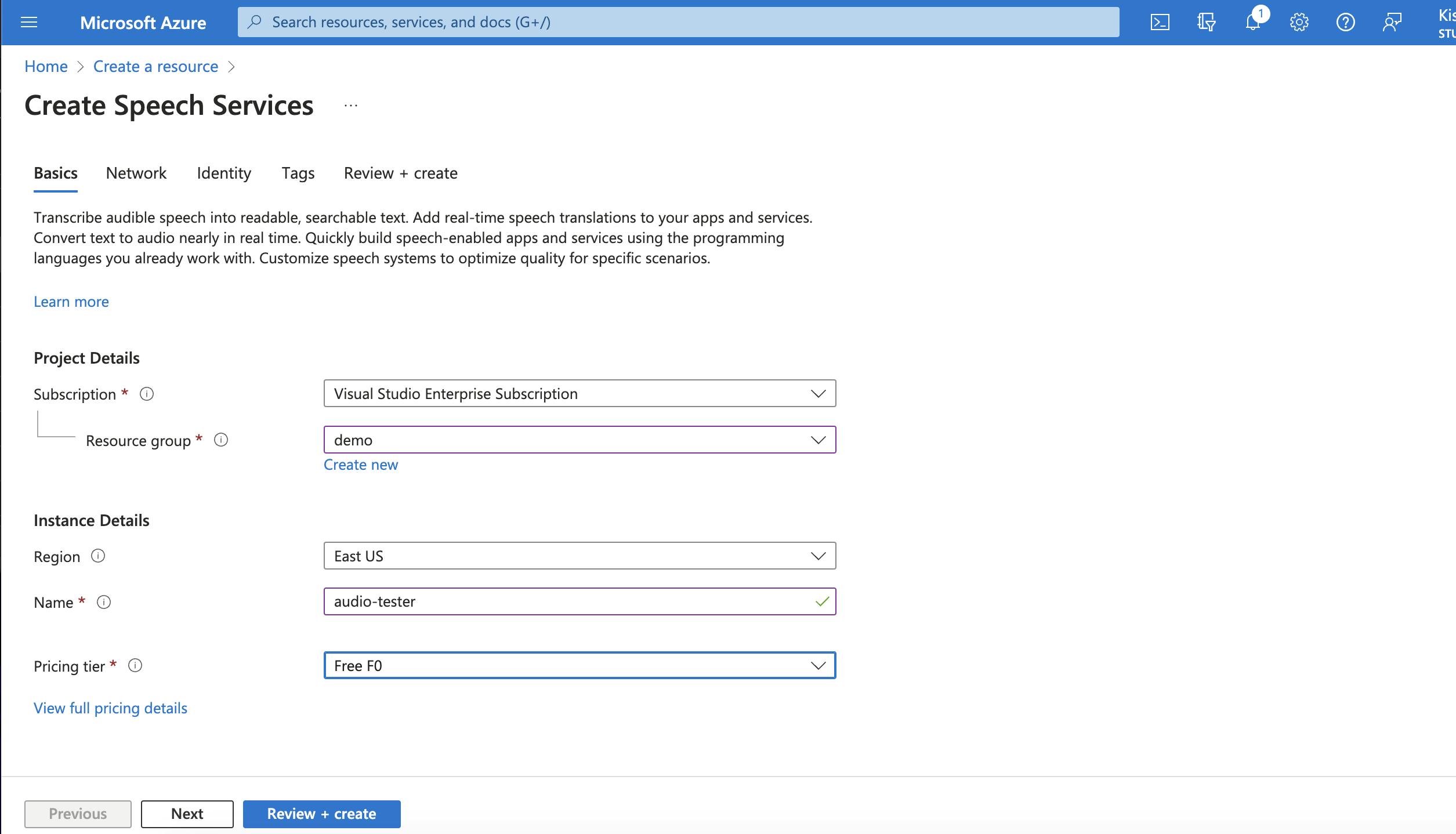
Continue to Create Resources, add details of Resource Group and pricing Tier, based on usage. Wait for deployment to succeed
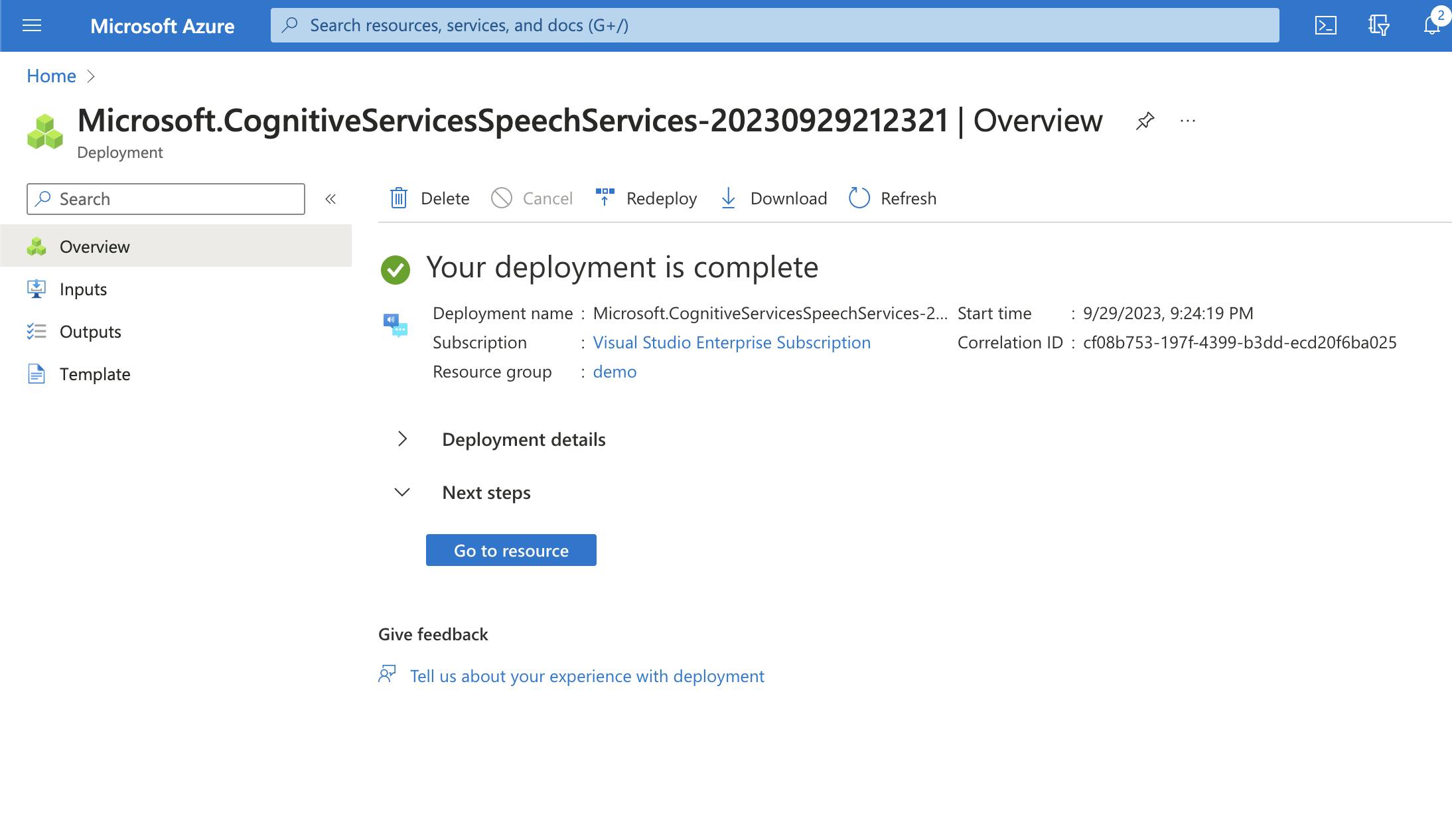
Open Resources and Review the overview. Save KEY 1 and Endpoint for further use.
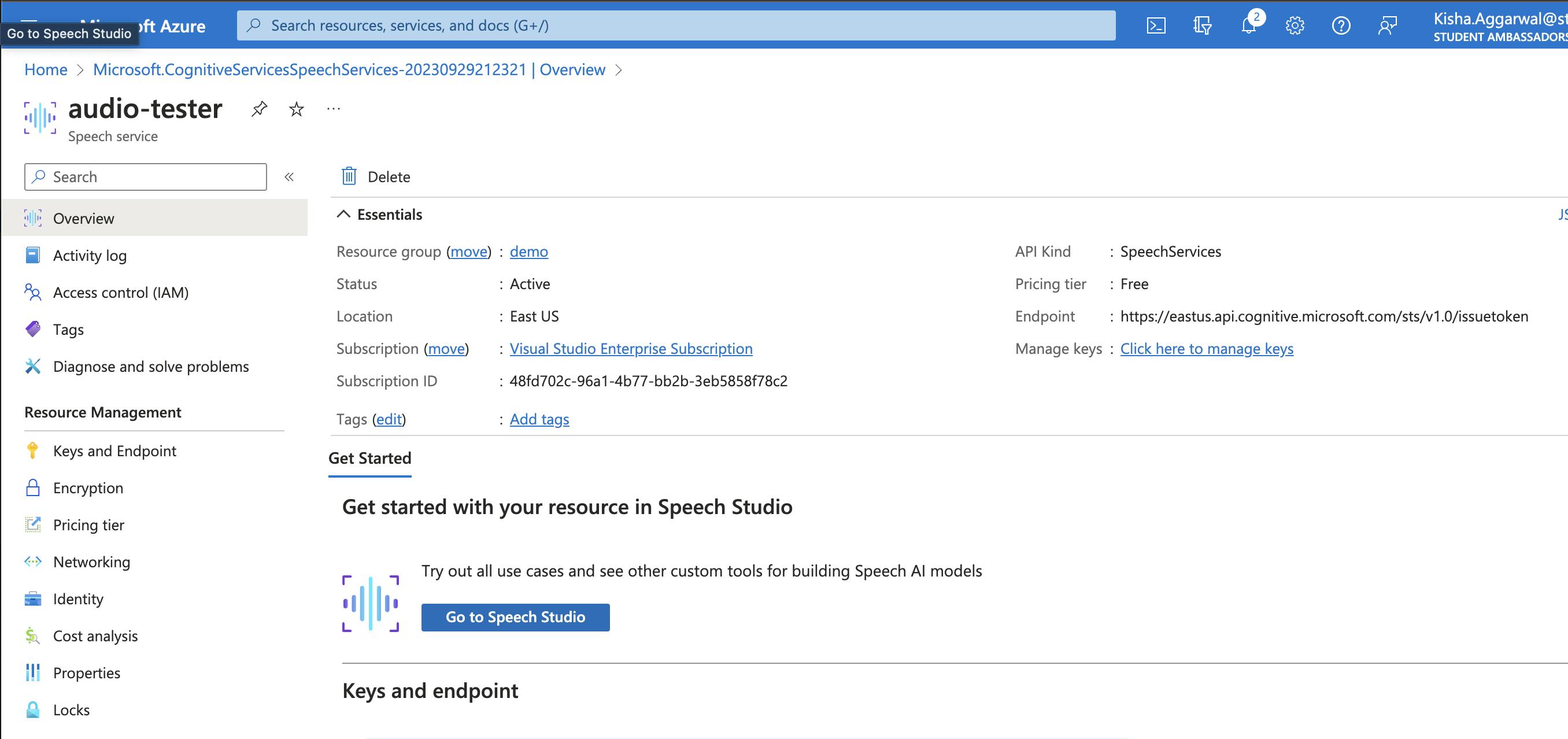
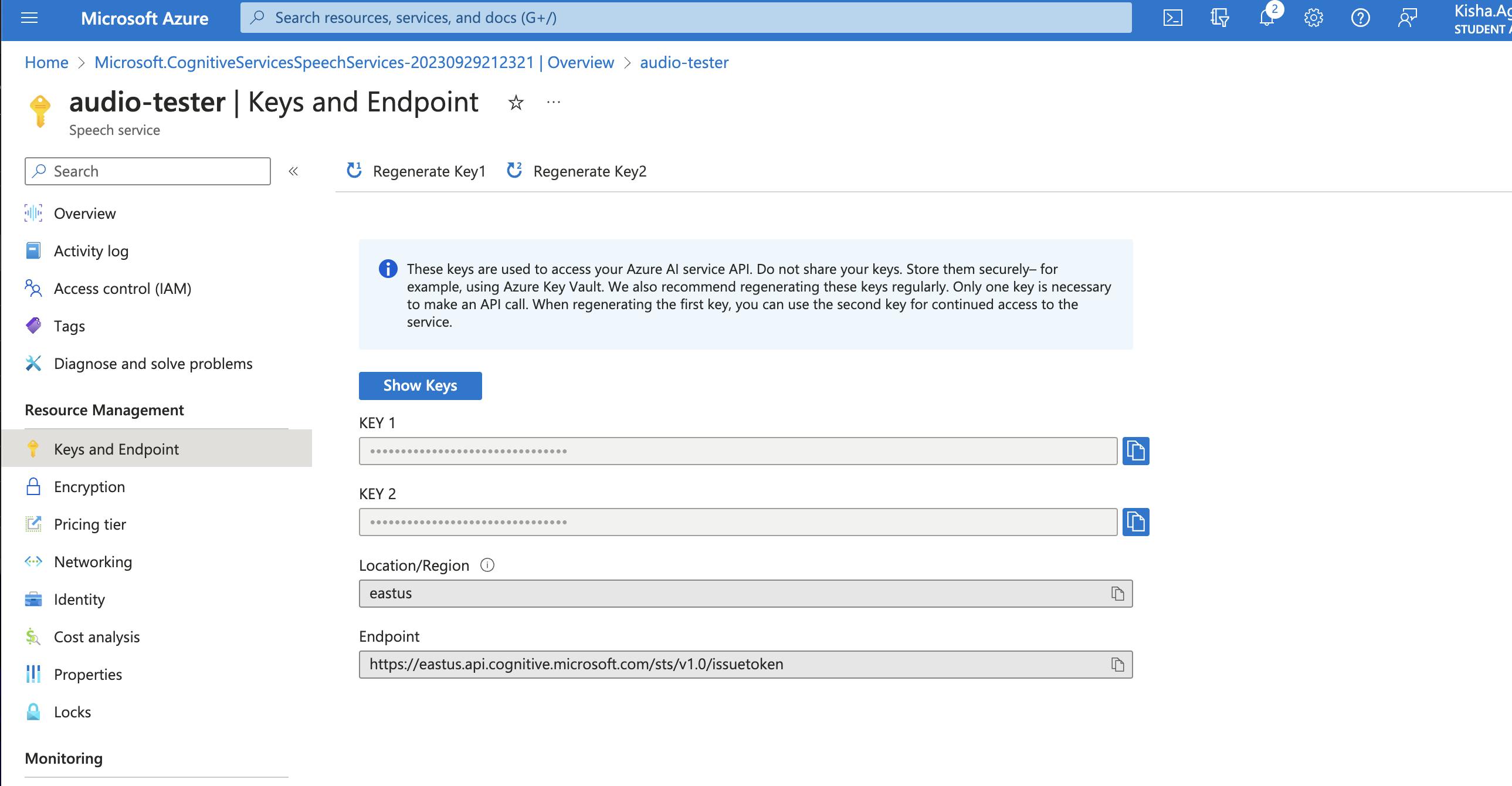
Review Speech Studio, Although it's not being used for this particular article
Step 2 - Installing Libraries
python3 -m venv venvsource venv/bin/activatepip install azure-cognitiveservices-speechIn your Local PC ensure, you are using OpenSSL >=1.1.0
openssl versionbrew install openssl
Step 3 - Code
Libraries & Client
import os
import azure.cognitiveservices.speech as speechsdk
endpoint = "https://eastus.api.cognitive.microsoft.com/sts/v1.0/issuetoken"
api_key = os.environ["API_KEY"]
subscription_key = os.environ["SUBSCRIPTION_KEY"]
# Speech Config
speech_config = speechsdk.SpeechConfig(subscription=api_key, region="eastus")
speech_config.speech_recognition_language = "en-US"
speech_config.endpoint_id = endpoint
Functions
Text-to-speech
def text_to_speech(text): speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config) result = speech_synthesizer.speak_text_async(text).get() if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted: print(f"Speech synthesized to speaker for text [{text}]") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech synthesis canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: if cancellation_details.error_details: print("Error details: {}".format(cancellation_details.error_details)) print("Did you update the subscription info?") if __name__ == "__main__": text_to_speech("Hello world")speech_synthesizer: This line creates an instance of theSpeechSynthesizerclass from the Azure SDK. Thespeech_configparameter specifies the configuration settings for the speech synthesis operation, which includes subscription and endpoint details.speech_synthesizer.speak_text_async(text): This method asynchronously synthesizes the inputtextinto speech. It takes the text you want to convert to speech as a parameter.result = speech_synthesizer.speak_text_async(text).get(): This line initiates the text-to-speech synthesis and waits for the result. Theget()method blocks execution until the synthesis is completed or cancelled. The result contains information about the synthesis operation.
Speech-to-Text
def speech_to_text(): speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config) print("Say something...") result = speech_recognizer.recognize_once_async().get() if result.reason == speechsdk.ResultReason.RecognizedSpeech: print(f"Recognized: '{result.text}'") elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print(f"Speech Recognition canceled: {cancellation_details.reason}") if cancellation_details.reason == speechsdk.CancellationReason.Error: print(f"Error details: {cancellation_details.error_details}")speech_recognizer: This line creates an instance of theSpeechRecognizerclass from the Azure SDK. It uses thespeech_configparameter, which contains the configuration settings for speech recognition, including subscription and endpoint details.print("Say something..."): This line simply prints a prompt to the user, indicating that they should say something for speech recognition.result = speech_recognizer.recognize_once_async().get(): This is the core of the speech recognition process. It asynchronously initiates a speech recognition operation using the microphone as input and waits for the result. Theget()method blocks execution until the recognition is completed or cancelled. The result contains information about the recognition operation.
Audio files to Text
# Audio file to text def audio_to_text(): #allowed_extensions = ["wav", "mp3", "wma", "ogg"] audio_input = speechsdk.AudioConfig(filename="myaudio.wav") speech_recognizer = speechsdk.SpeechRecognizer( speech_config=speech_config, audio_config=audio_input ) result = speech_recognizer.recognize_once_async().get() if result.reason == speechsdk.ResultReason.RecognizedSpeech: print(f"Recognized: '{result.text}'") elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print(f"Speech Recognition canceled: {cancellation_details.reason}") if cancellation_details.reason == speechsdk.CancellationReason.Error: print(f"Error details: {cancellation_details.error_details}")allowed_extensions = ["wav", "mp3", "wma", "ogg"]audio_input: This line creates an instance of theAudioConfigclass from the Azure SDK. It specifies the audio input source for speech recognition, which in this case is an audio file named "myaudio.wav." You can change the filename to the path of the audio file you want to transcribe.speech_recognizer: This line creates an instance of theSpeechRecognizerclass from the Azure SDK. It uses thespeech_configparameter, which contains the configuration settings for speech recognition, and theaudio_configparameter, which specifies the audio input source.Recognition Operation:
result = speech_recognizer.recognize_once_async().get(): This line initiates the speech recognition operation asynchronously and waits for the result. Theget()method blocks execution until the recognition is completed or cancelled. The result contains information about the recognition operation.
Batch Transformation Audio files to Text
def batch_transcription(audio_files): """Batch transcription of audio files""" audios = [] for audio_file in audio_files: audio_config = speechsdk.AudioConfig(filename=audio_file) audios.append(audio_config) speech_recognizer = speechsdk.SpeechRecognizer( speech_config=speech_config, audio_config=audios[0] ) result = speech_recognizer.recognize_once_async().get() if result.reason == speechsdk.ResultReason.RecognizedSpeech: print(f"Recognized: '{result.text}'") elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print(f"Speech Recognition canceled: {cancellation_details.reason}") if cancellation_details.reason == speechsdk.CancellationReason.Error: print(f"Error details: {cancellation_details.error_details}")audiosList: Inside the function, there is a loop that iterates through a list ofaudio_files. For each audio file in the list, it creates an instance of theAudioConfigclass using the file's name and appends it to theaudioslist. This prepares a list of audio configurations to be used for batch transcription.speech_recognizer: After creating the list of audio configurations, the function creates an instance of theSpeechRecognizerclass from the Azure SDK. It uses thespeech_configparameter, which contains the configuration settings for speech recognition, and sets theaudio_configto the first audio configuration in theaudioslist.Recognition Operation:
result = speech_recognizer.recognize_once_async().get(): This line initiates the speech recognition operation asynchronously for the first audio file in the batch and waits for the result. Theget()method blocks execution until the recognition is completed or cancelled. The result contains information about the recognition operation for the first audio file.
Conclusion
In the ever-evolving tech landscape, Azure Cognitive Services' Speech API emerges as a transformative force, redefining human-computer interaction. This guide has delved into its versatile functionalities, from text-to-speech synthesis to speech-to-text transcription with impressive precision, and even emotion detection. Whether creating voice assistants, bolstering accessibility, or crafting immersive user experiences, the Azure Speech API empowers developers to connect with users on a profound level. As we conclude, we recognize its potential to usher in a future where technology communicates with us in our natural language, making applications more intuitive, inclusive, and emotionally attuned. It's not just a tool; it's a catalyst for the evolution of voice technology, where applications listen, speak, and empathize, bridging the gap between humans and machines.